Microsoft Fabric is an end-to-end analytics platform that provides a single, integrated environment for data professionals and the business to collaborate on data projects. 1

Fabric provides a set of integrated services that enable you to ingest, store, process, and analyze data in a single environment.
Contents
Introduction to Microsoft Fabric

1. Introduction to Microsoft Fabric
Fabric is built on Power BI and Azure Data Lake Storage, and includes capabilities from Azure Synapse Analytics, Azure Data Factory, Azure Databricks, and Azure Machine Learning.
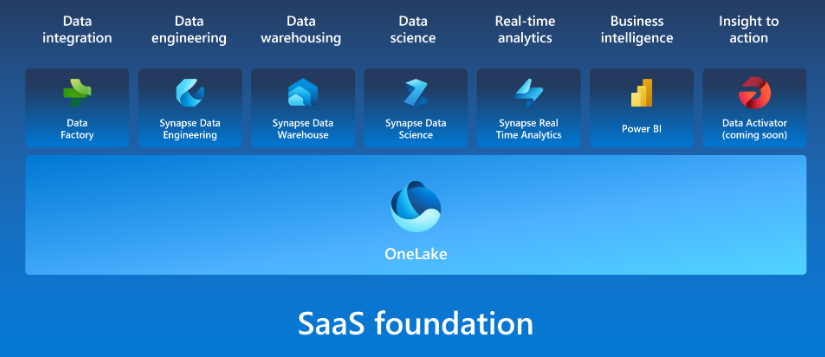
Services
| Data engineering | Synapse Data Engineering | data engineering with a Spark platform for data transformation at scale. |
| Data integration | Data Factory | data integration combining Power Query with the scale of Azure Data Factory to move and transform data. |
| Data warehousing | Synapse Data Warehouse | data warehousing with industry-leading SQL performance and scale to support data use. |
| Real-time analytics | Synapse Real-Time Analytics | real-time analytics to query and analyze large volumes of data in real-time. |
| Data science | Synapse Data Science | data science with Azure Machine Learning and Spark for model training and execution tracking in a scalable environment. |
| Business intelligence | Power BI | business intelligence for translating data to decisions. |
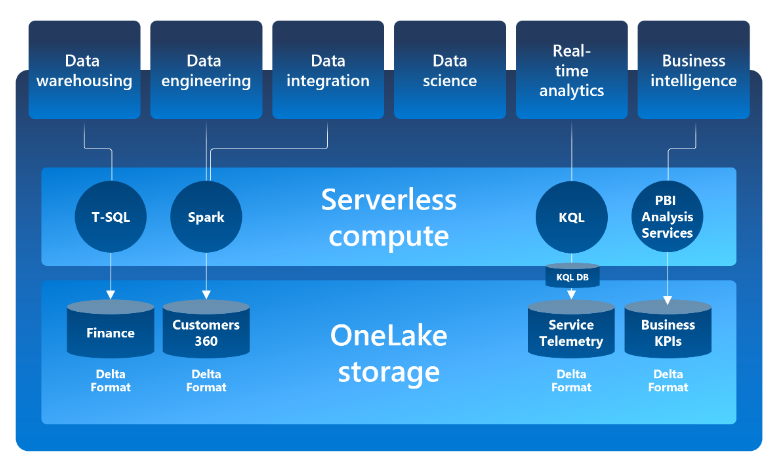
OneCopy is a key component of OneLake that allows you to read data from a single copy, without moving or duplicating data.
OneLake is built on top of Azure Data Lake Storage (ADLS) and data can be stored in any format, including Delta, Parquet, CSV, JSON, and more.
Fabric uses Microsoft Purview Information Protection’s sensitivity labels to help your organization classify and protect sensitive data, from ingestion to export.

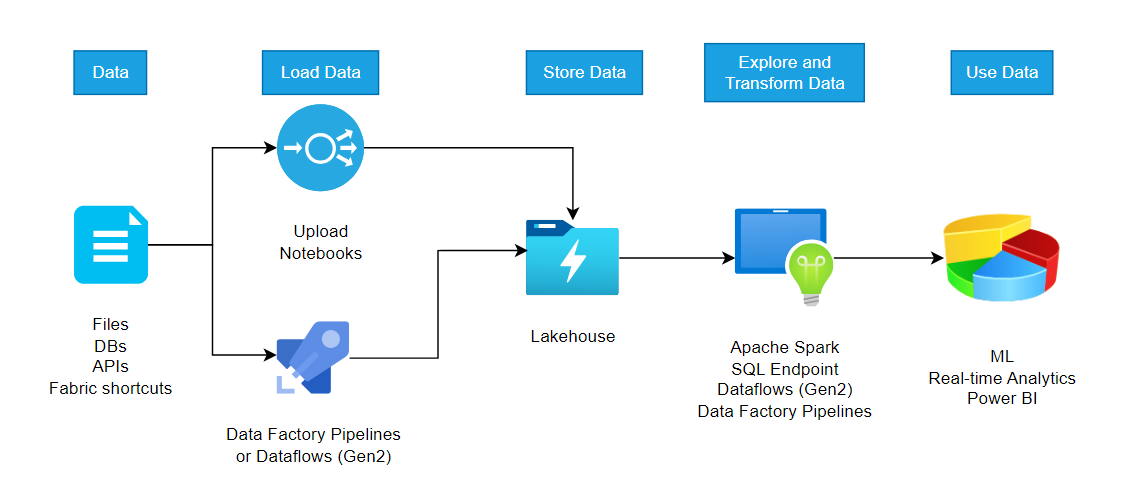
2. Lakehouse
built on top of the OneLake scalable storage layer and uses Apache Spark and SQL compute engines for big data processing
- The flexible and scalable storage of a data lake
- The ability to query and analyze data of a data warehouse
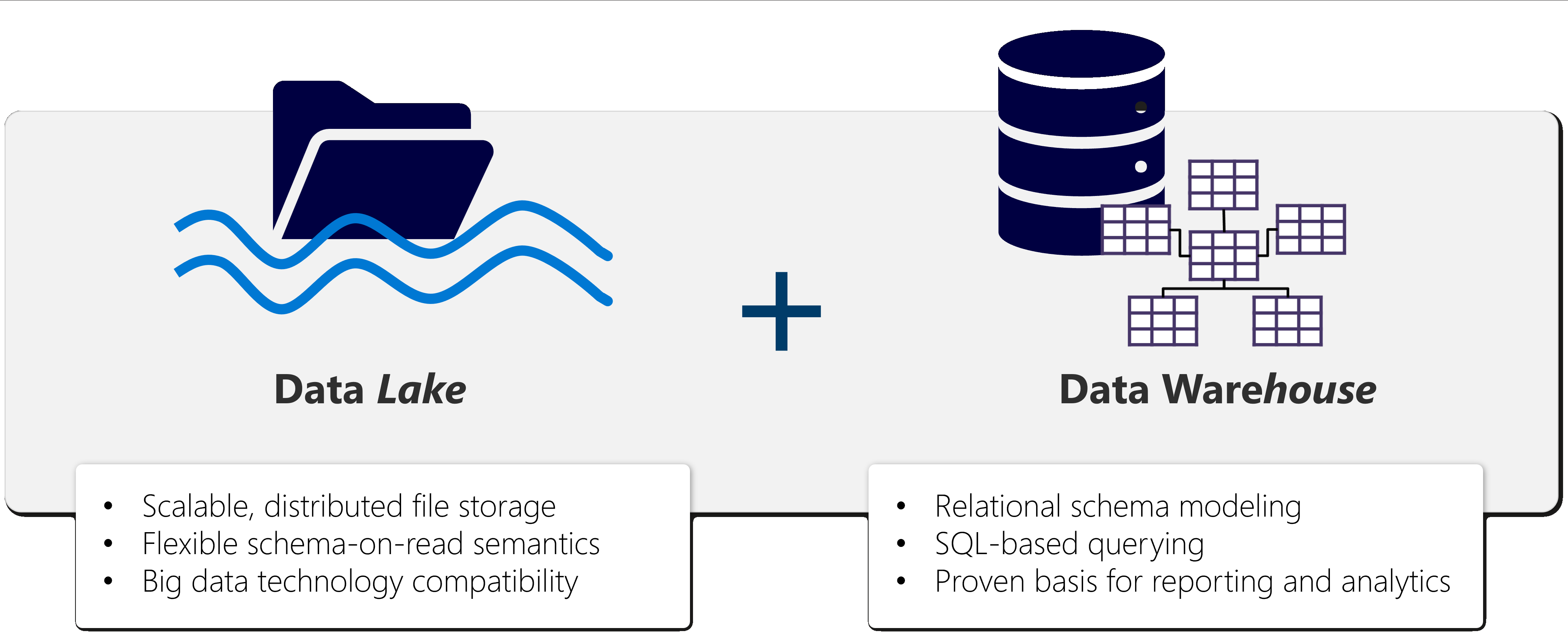
Benefits
- Lakehouses use Spark and SQL engines to process large-scale data and support machine learning or predictive modeling analytics.
- Lakehouse data is organized in a schema-on-read format, which means you define the schema as needed rather than having a predefined schema.
- Lakehouses support ACID (Atomicity, Consistency, Isolation, Durability) transactions through Delta Lake formatted tables for data consistency and integrity.
- Lakehouses are a single location for data engineers, data scientists, and data analysts to access and use data.
Three named items
- Lakehouse is the lakehouse storage and metadata, where you interact with files, folders, and table data and enables you to add and interact with tables, files, and folders in the Lakehouse.
- Dataset (default) is an automatically created data model based on the tables in the lakehouse. Power BI reports can be built from the dataset.
- SQL Endpoint is a read-only SQL endpoint through which you can connect and query data with Transact-SQL and enables you to use SQL to query the tables in the lakehouse and manage its relational data model.

Helen Grek
3. Apache Spark
is a distributed data processing framework that enables large-scale data analytics by coordinating work across multiple processing nodes in a cluster.
Available in
- Azure HDInsight
- Azure Databricks
- Azure Synapse Analytics, and
- Microsoft Fabric
Code
Spark can run code in:
- Java
- Scala (a Java-based scripting language)
- Spark R
- Spark SQL
- PySpark (a Spark-specific variant of Python).
Most popular are PySpark and Spark SQL
Libraries
- Feed library: Feed libraries come from public sources or repositories.
- Custom library: Custom libraries are the code built by you or your organization
| Library | Workspace update | In-line installation |
| Python Feed (PyPI & Conda) | + | + |
| Python Custom (.whl) | + | + |
| R Feed (CRAN) | – | + |
| R custom (.tar.gz) | + | + |
| Jar | + | – |
Run Code
Notebook – to combine text, images, and code written in multiple languages to create an interactive artifact that you can share with others and collaborate.
Spark job definition – to ingest and transform data as part of an automated process, to run a script on-demand or based on a schedule
Work with data in a Spark dataframe 2
- Loading data into a dataframe
- Inferring a schema
- Specifying an explicit schema
- Filtering and grouping dataframes
- Saving a dataframe
- Partitioning the output file
- Load partitioned data
Work with data using Spark SQL
- Creating database objects in the Spark catalog
- Using the Spark SQL API to query data
- Using SQL code
Visualize data in a Spark notebook
- Using built-in notebook charts
- Using graphics packages in code
4. Delta Lake tables
Tables in a Microsoft Fabric lakehouse are based on the Linux foundation Delta Lake table format, commonly used in Apache Spark
Marked by a triangular Delta (▴) icon on tables
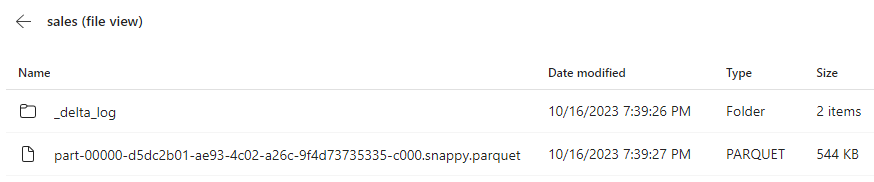
For each table, folder containing:
- Parquet data files and
- _delta_Log folder in which transaction details are logged in JSON format.
Benefits of Delta tables:
- Relational tables that support querying and data modification.
Support CRUD (create, read, update, and delete) operations, i.e. select, insert, update, and delete as in a relational database system
- Support for ACID transactions.
- Atomicity (transactions complete as a single unit of work),
- Consistency (transactions leave the database in a consistent state),
- Isolation (in-process transactions can’t interfere with one another),
- Durability (when a transaction completes, the changes it made are persisted)
- Data versioning and time travel.
Because all transactions are logged in the transaction log
Older versions of the data (known as time travel)
- Support for batch and streaming data.
Through the Spark Structured Streaming API
Delta Lake tables: sinks (destinations) or sources for streaming data
- Standard formats and interoperability.
The underlying data is stored in Parquet format
Use the SQL Endpoint for the Microsoft Fabric lakehouse to query Delta tables in SQL
Create delta tables
- Creating a delta table from a dataframe
Managed vs external tables - Creating table metadata
Use the DeltaTableBuilder API - Use Spark SQL
- Saving data in delta format
Work with delta tables in Spark
- Using Spark SQL
- Use the Delta API
- Use time travel to work with table versioning
Use delta tables with streaming data
- Spark Structured Streaming
- Streaming with delta tables
– Using a delta table as a streaming source
– Using a delta table as a streaming sink
- The source of the Notes is Microsoft Fabric Challenge ↩︎
- You can find code examples in the link above ↩︎

SUBSCRIBE to my channels to learn more about data analytics and engineering and stay updated with the latest news.


Leave a Reply